From Chaos to Consistency
Tackling the Marking Challenge with AI

In Semester 1 of 2025, I found myself managing a class of over 530 students and coordinating feedback across eight tutors. It was a logistical mountain. Each tutor brought valuable expertise, but also their own marking style, level of experience, and pace. Despite everyone’s best efforts, inconsistencies began to creep in. Some students received rich, constructive feedback, while others got short or overly generic comments. The sheer scale made it nearly impossible to guarantee fairness and depth for every learner.
If you’ve ever coordinated assessment across a large class, you know the struggle. Multiple tutors, each with their own experience level and marking style. Time pressures that make it hard to offer quality feedback. Students frustrated by comments that feel generic, or worse, unfair. It’s a perfect storm that leaves everyone feeling dissatisfied.
Marking at scale isn’t just about consistency; it’s about care. Students deserve meaningful, individualized feedback, and tutors deserve systems that make this possible without burning them out. This is where large language models (LLMs) can quietly transform the marking process; not by replacing human judgment, but by amplifying it.
The first part of this post is about a system I created myself, but as you will find out at the end, the same thing can be achieved with ChatGPT.
Aligning AI Feedback with Rubrics
The idea is simple: instead of leaving feedback entirely to either humans or machines, we can align both.
Tutors select the relevant rubric criteria, either through checkboxes or numerical scores, and an LLM translates those selections into personalised, context-aware comments. Optional student work, such as code or essays, can also be incorporated for finer feedback. The result is feedback that’s consistent, individualized, and grounded in the same rubric that underpins assessment.
This approach keeps tutors in the loop but removes the friction of repetitive comment writing. It also ensures students receive feedback that feels authentic and fair. Something grounded in both human evaluation and linguistic nuance.
Building the System: My Prototypes
Over the past year, I experimented with this concept by developing simple webpages hosted on my own server, all connected to the OpenAI API. The goal was to see how far AI could go in improving marking workflows.
Prototype 1: Fully Automated (GPT-3)
The system provided the AI with the rubric, assignment description, and student files. GPT-3 generated both marks and feedback automatically. While quick, it was far too generous and occasionally wrong. The tone was polished, but the accuracy wasn’t there.
The rubric and assignment description files were stored on the web server. All the markers had to do was drag and drop the student submission onto the webpage.
After pressing submit and a little waiting time, the AI would respond with an evaluation of the assignment as shown here:

Prototype 2: Iterative Automation (GPT-4)
This version improved by first asking the model to apply the rubric, then generate marks and feedback in a two step process. The results were better in that they were more balanced and more personal, but still inconsistent in edge cases.
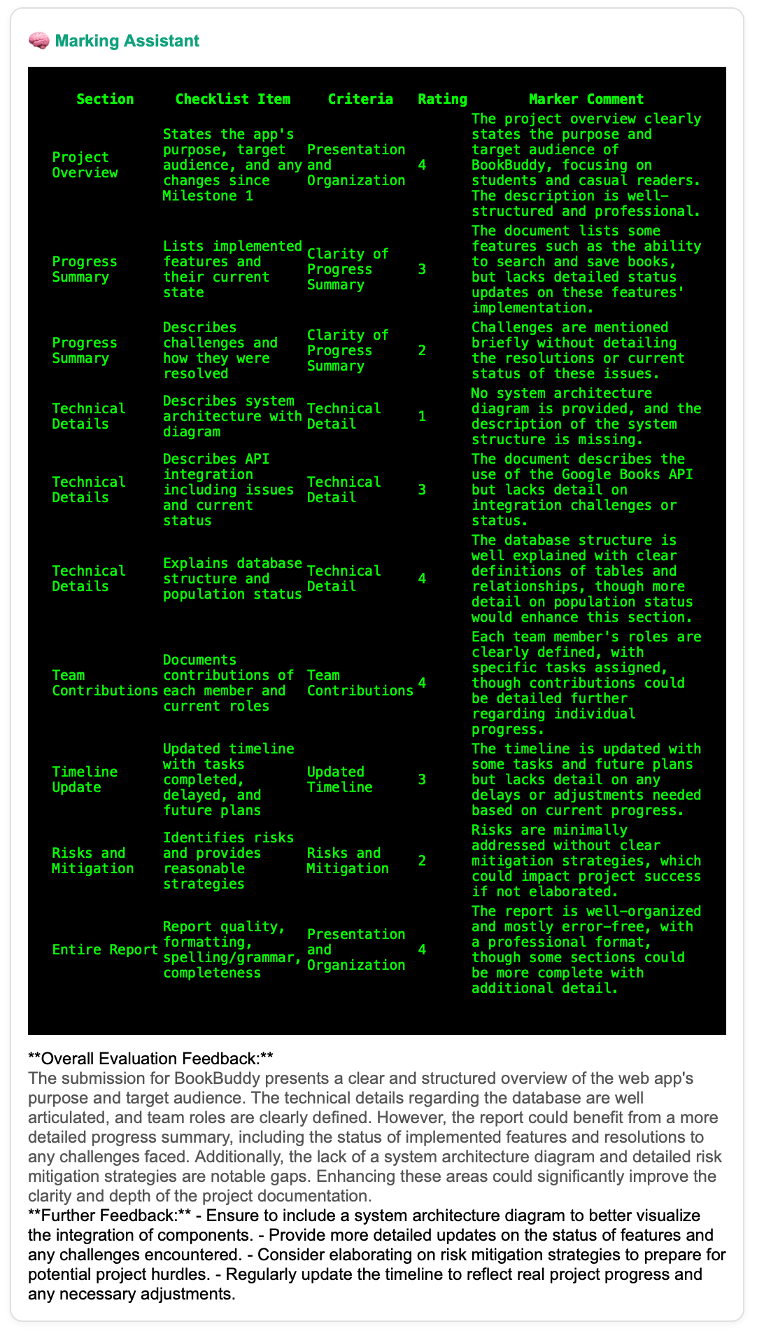
Prototype 3: Human in the Loop
The breakthrough came when I combined human judgment with AI assistance. Human markers completed the rubric first, and the model used that input to generate contextualized feedback. The comments aligned tightly with both the scores and the assignment description. The difference was immediate: accuracy up, marking fatigue down, and tutors reported feeling more confident in their feedback.
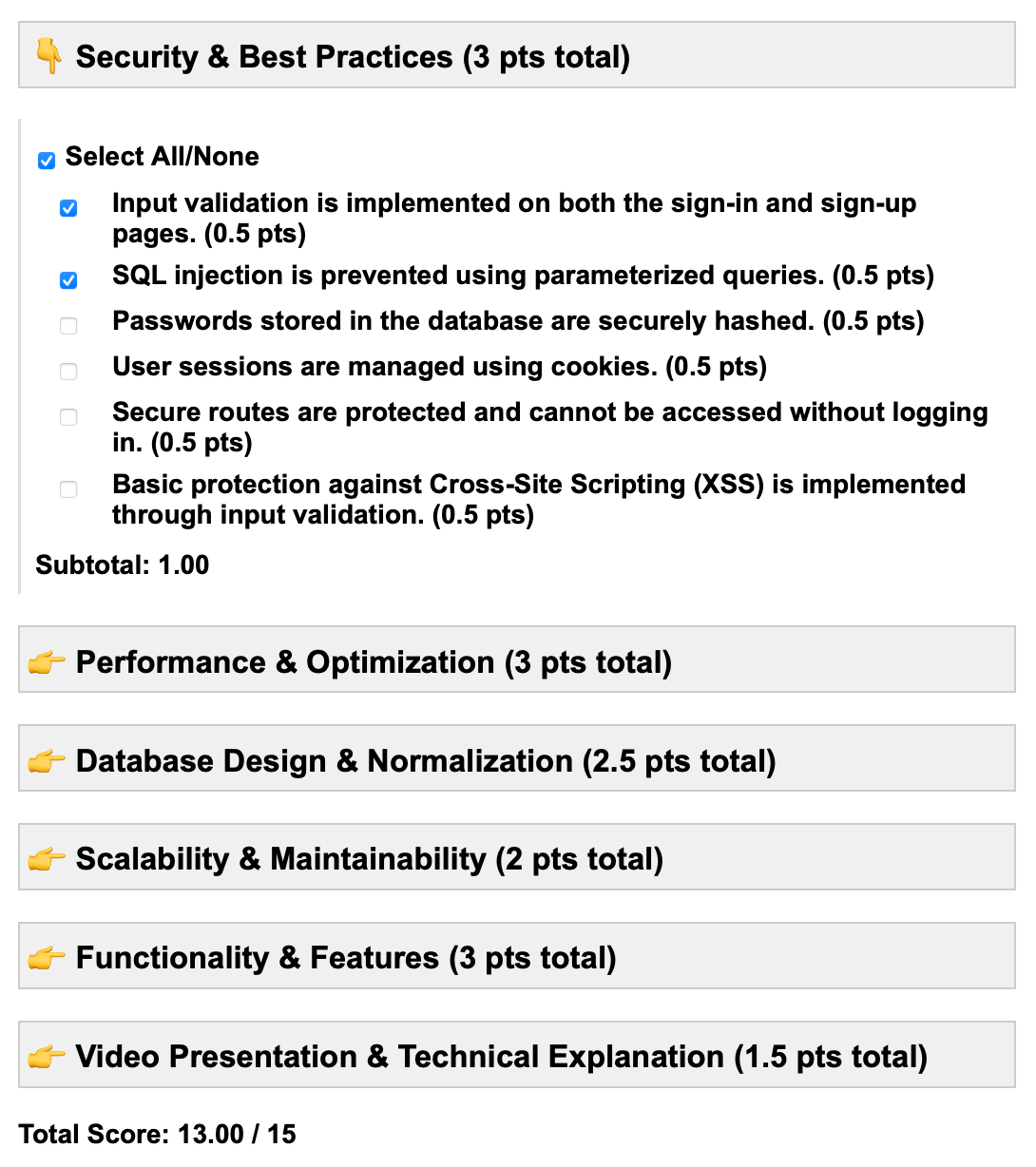
The results after submission:

Using ChatGPT instead (or any other LLM)
For those of you without the coding now how, I was interested in determining if the same process could be done using ChatGPT. And it can! Just by submitted a spreadsheet with the completed marking.
The spreadsheet, that you can get via this link includes the prompts, rubrics and human assessment marks. This is simply copy and pasted into ChatGPT and what results is a nice little report, which the markers can then pick and choose the feedback from to provide students with the greatest personalised and relevant feedback.
See how it can be done in this video:
What We Gain
1. Tutors and Markers
Reduced fatigue through automation of repetitive phrasing
Greater consistency across multiple markers
Focus on judgment, not wording
As Willey and Gardner (2010) put it:
“Engaging in structured marking practices enhances tutors’ confidence, fosters professional growth, and promotes reflective teaching.”
2. Students
Timely, specific, and consistent feedback
A clearer understanding of performance criteria
Improved motivation and self-regulation
Foster (2024) found that:
“Formative assessment practices that deliver timely, specific, and consistent feedback significantly improve student learning outcomes, motivation, and self-regulation.”
Impacts and Insights
In practice, the system produced:
Increased tutor confidence and alignment
Faster turnaround times for returning results
A scalable framework for consistent, personalized feedback in future course offerings
And perhaps most importantly, it reframed AI not as a shortcut, but as a support structure. One that helps humans focus on what they do best: judgment, mentoring, and care.
Closing Reflection
As I’ve written in The AI Educator, automation in education should never be about replacing teachers. It’s about reclaiming time and clarity. When used thoughtfully, AI can take over the heavy lifting of routine tasks so educators can spend more time engaging with students, not spreadsheets. The goal is not to make marking faster, but to make feedback fairer, more human, and more meaningful at scale.
Because in the end, it’s not just about the marks as much as it’s about learning.
References
Foster, H. (2024). The impact of formative assessment on student learning outcomes: A meta-analytical review. Academy of Educational Research Journal, 28(1), 15–32.
Willey, K., & Gardner, A. (2010). Improving the standard and consistency of multi-tutor grading in large classes.University of Technology Sydney.